C语言嵌入式--数据存储与指针笔记6
本文共 2697 字,大约阅读时间需要 8 分钟。
(一)程序优化思路
- 算法:减少指令数,提高运行效率
- 缓存:改变数据的存储方式、读写速度
(二)存储的基本概念
- 存储单元
| 存储单元 | 描述 |
|---|---|
| 位 | 计算机存储的最小单位 |
| 字节 | 计算机常用的存储单位 |
| 字 | 开发者常用 |
思考1:一个字一定占4个字节吗?
不一定。由所使用的编译器决定,编译器的分配策略又是由cpu架构决定,cpu架构最终由指令集决定(采用的指令集决定了cpu架构的设计)
- 存储模式
| 存储模式 | 描述 |
|---|---|
| 大端模式 | 高地址存储低字节数据 低地址存储高字节数据 |
| 小端模式 | 高地址存储高字节数据 低地址存储低字节数据 |
思考2:什么是位序和字节序?
位序:一个字节里的各个位的存放顺序
字节序:两个或者两个以上字节数据中,一个字节的存放顺序
- 如何判断大端模式与小端模式(32位机)
方法1(常规):
int val = 0x11223344;char tmp;tmp = val;if (val == 0x11){ printf("Big Endian.\n\r");}else{ printf("Little Endian.\n\r");} 方法2(联合):
union value { //所有变量共享内存 int a; char b;}val;val.a = 0x11223344;if (val.a == 0x11){ printf("Big Endian.\n\r");}else{ printf("Little Endian.\n\r");} 思考2:为什么会有大小端之分?
1 小端符合人的思维习惯
2 大端符合计算机运算逻辑。不需要考虑对应关系,按照字节把数据从左往右、由低到高的字节序进行读写 3 大端一般用在网络字节序和各种编解码中PS:嵌入式处理器的寄存器:MSB、LSB
- 数据的大小端转换(32位机)
#define swap_endian_u32(value) { \ (((value) & 0xff000000 >> 24) | ((value) & 0x00ff0000 >> 8) \ |((value) & 0x0000ff00 << 8) | ((value) & 0x000000ff << 24)) \} int main(void){ int v = 0x11223344; //int value = swap_endian_u32(v) ; int value = (((x) & 0xff) << 24) + (((x >> 8) & 0xff)<<16) + (((x >> 16) & 0xff) << 8) + (((x >> 24) & 0xff)); printf("value = 0x%x\n", value); return 0; } (三)有符号数与无符号数
- 原码、反码和补码
1 计算机采用补码存储数据
2 无符号数的存储:原码、反码和补码相同 3 有符号数的存储:a 有符号数采用补码的形式存储
b 有符号数反码:最高位保持不变,其它位按位取反 c 有符号数补码:反码+1
- 计算机为什么要使用补码来存储数据?
1 解决0的编码问题 2 减法运算可以转换为加法,省去硬件的减法电路。CPU只要有全加器、求补电路即可 3 符号位也能参与运算,和其它位统一处理。有补码表示的数相加,最高位有进位时,则进位被舍弃
(四)数据溢出
无符号数的溢出:取模运算,继续“轮回”
unsigned char c = 255;printf("c = %u\n",c);c++;printf("C = %u\n",c); 有符号数的溢出:
不会触发异常:C语言的宽松性、不作类型安全性检查
会产生未定义行为
signed char c2 = 127;printf("c2 = %d\n",c2);c2++;printf("c2 = %d\n",c2);//由编译器决定. gcc编译器对有符号数的数据溢出也是“轮回” - 如何防范整数溢出?
有符号数相加:两个正数相加小于0; 两个负数相加大于0
char a = 125;char b = 30;if((unsigned char)a+(unsigned char)b > SCHAR_MAX) printf("data overflow!\n");char c = a + b;printf("%d\n",c); 无符号数相加:两个数相加,和小于其中任何一个加数
unsigned char a = 255;unsigned char b = 40;unsigned char c;c = a + b;if(c < a || c < b) printf("data overflow!\n");printf("c = %u\n",c); (五)数据对齐
数据对齐原则:基本类型数据成员按自然边界对齐
为什么要数据对齐?–>CPU硬件限制不同硬件平台对存储空间的管理不同
为了简化CPU硬件设计,简化了地址访问 编译器会根据硬件平台选择合适的对齐方式
- 结构体对齐原则? •结构体内各成员按各自自然对齐方式 •结构体整体对齐方式:按最大成员对齐或其整数倍
联合体对齐原则
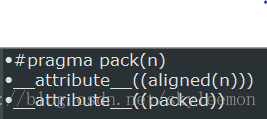
•按最大成员大小分配空间 •联合体的对齐:各成员对齐字节数的最小公倍数显示指定对齐方式(两种方法)
(六)数据类型转换
- 为什么要类型转换 1 计算机CPU执行运算时的硬件要求 2 类型、大小、存储方式要相同
- 转换方式 1 隐式类型转换 2 强制类型转换
- 隐式类型转换 •算术、逻辑、赋值表达式中数据类型不同 •函数形参与实参类型不匹配 •函数返回值类型与函数类型不匹配
- 隐式类型转换 •低精度->高精度 有符号->无符号 •signed->unsigned •char -> short -> int -> unsigned -> long -> double -> long double •char -> short ->int ->long ->long long ->float ->double ->…
- 强制类型转换 •char—int:值不变、存储格式发生变化 •int—char:截断 •signed—unsigned:值改变,存储格式不发生变化
你可能感兴趣的文章
链表各类操作详解
查看>>
C++实现 简单 单链表
查看>>
数据结构之单链表——C++模板类实现
查看>>
Linux的SOCKET编程 简单演示
查看>>
正则匹配函数
查看>>
Linux并发服务器编程之多线程并发服务器
查看>>
聊聊gcc参数中的-I, -L和-l
查看>>
[C++基础]034_C++模板编程里的主版本模板类、全特化、偏特化(C++ Type Traits)
查看>>
C语言内存检测
查看>>
Linux epoll模型
查看>>
Linux系统编程——线程池
查看>>
Linux系统编程——线程池
查看>>
yfan.qiu linux硬链接与软链接
查看>>
Linux C++线程池实例
查看>>
shared_ptr简介以及常见问题
查看>>
c++11 你需要知道这些就够了
查看>>
c++11 你需要知道这些就够了
查看>>
shared_ptr的一些尴尬
查看>>
C++总结8——shared_ptr和weak_ptr智能指针
查看>>
c++写时拷贝1
查看>>